决策树的原理及实现
条评论前言
不得不说,相对于前面几章,决策树的新鲜知识点明显要多了,引入了很多信息论中的内容,看的很难受呀,不过在信念的坚持下,还是开始总结了本章的知识点。
决策树是一种基本的分类与回归方法。本篇文章主要讨论分类的决策树,决策树呈现树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以被认为是if-then规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。主要优点是模型具有可读型、分类速度快,学习时,利用训练数据,根据损失函数最小化的原则建立决策树模型;预测时,对新的数据利用决策树模型进行分类,决策树学习通常包括3个步骤:特征选择、决策树的生成和决策树的修剪。
决策树模型与学习
决策树模型
定义5.1(决策树) 分类决策树模型是一种描述对实例进行分类的树形结构,决策树由结点(node)和有向边(directed edge)组成。结点有两种类型,内部结点(internal node)和叶结点(leaf node)。内部结点表示一个特征或属性,叶结点表示一个类。
用决策树分类,从根节点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子结点;这时,每一个子结点对应着该特征的一个取值,如此递归地对实例进行测试并分配,直至达到叶结点。最后将实例分到叶结点的类中。
决策树与if-then规则
可以将决策树看成一个if-then规则的集合。将决策树转换成if-then规则的过程是这样的:由决策树的根结点到叶结点的每一条路径构建一条规则;路径上内部结点的特征对应着规则的条件,而叶结点的类对应着规则的结论。决策树有着互斥并且完备这一特点。就是说,每一个实例都被一条路径或一条规则所覆盖,并且只被一条路径或一条规则所覆盖。
决策树与条件概率分布
决策树还表示给定特征条件下类的条件概率分布。这一条件概率分布定义。这一条件概率分布定义在特征空间上的一个划分上。将特征空间划分为互不相交的单元或区域,并在每个单元定义一个类的概率分布就构成了一个条件概率分布。决策树的一条路径对应于划分中的一个单元,决策树所表示的条件概率分布由各个单元给定条件下类的条件概率分布组成。假设X为表示特征的随机变量,Y为表示类的随机变量,那么这个条件概率分布可以表示为P(Y|X)。X取值于给定划分下单元的集合,Y取值于类的集合。各叶结点(单元)上的条件概率往往偏向某一个类,即属于某一类的概率较大。决策树分类时将该结点强行分到条件概率大的那一类去。
决策树学习
决策树学习,假设给定训练数据集$$D=\{(x_1,y_1),(x_2,y_2),…,(x_N,y_N)\}$$其中,$x_i=(x_i^{(1)},x_i^{(2)},…,x_i^{(n)})^T$为输入实例(特征向量),$n$为特征个数,$y_i\in \{1,2,…,K\}$为类标记,$i=1,2,…,N$,$N$为样本容量,学习的目标是根据给定的训练数据集构建一个决策树模型,使它能够对实例进行正确的分类。
决策树学习本质上是从数据集中归纳出一组分类规则。与训练数据集不相矛盾的决策树可能有多个,也可能一个也没有。我们需要的是一个与训练数据矛盾较小的决策树,同时具有很好的泛华能力。
当损失函数确定以后,学习问题就变为在损失函数意义下选择最优决策树的问题。因为从所有可能的决策树中选取最优决策树是NP完全问题,所以现实中决策树学习算法通常采用启发式方法,近似求解这一最优化问题。这样得到的决策树是次最优的。
决策树学习的算法通常是一个递归地选择最优特征,并根据特征对训练数据进行分割,使得对各个子数据集有一个最好的分类的过程。这一过程对应着对特征空间的划分,也对应着决策树的构建。开始,构建根结点,将所有训练数据都放在根结点。选择一个最优特征,按照这一特征将训练数据集分割成子集,使得各个子集有一个在当前条件下最好的分类。如果这些子集已经能够被基本正确分类,那么构建叶结点,并将这些子集分到所对应的叶结点中去;如果还有子集不能被基本正确分类,那么就对这些子集选择新的最优特征,继续对其进行分割,构建相应的结点。如果递归地进行下去,直至所有训练数据集被基本正确分类,或者没有合适的特征为止,最后每个子集都被分到叶结点上,即都有了明确的类。这就生成了一课决策树。
以上方法生成的决策树可能对训练数据集有很好的分类能力,但对未知的测试数据却未必有很好的分类能力,即可能发生过拟合现象。我们需要对已生成的树自下向上而进行剪枝,将树变得更简单,从而使它具有更好的泛化能力。具体地,就是去掉过于细分的叶结点,使其回退到父结点,甚至更高的结点,然后将父结点或更高的结点改为新的叶结点。
特征选择
特征选择问题
特征选择在于选取对训练数据具有分类能力的特征。这样可以提高决策树学习的效率。如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则称这个特征是没有分类能力的。经验上扔掉这样的特征对决策树学习的精度影响不大。通常特征选择的准则是信息增益或信息增益比。
信息增益
在信息论与概率统计中,熵(entropy)是表示随机变量不确定性的度量。设$X$是一个取有限个值的离散随机变量,其概率分布为$$P(X=x_i)=p_i ,i=1,2,…,n$$则随机变量$X$的熵定义为$$H(X)=-\sum_{i=1}^{n}{p_i log p_i}$$在式中,若$p_i=0$,则定义$0log0=0$。通常,该式中的对数以2为底或以e为底(自然对数),这时熵的单元分别称作比特或纳特。由定义可知,熵只依赖于X的分布,而与X的取值无关,所以也可将X的熵记作$H(p)$,即$$H(p)=-\sum_{i=1}^{n}p_i log p_i$$
熵越大,随机变量的不确定性就越大,当$p=0$或$p=1$时$H(p)=0$,随机变量完全没有不确定性。当$p=0.5$时,$H(p)=1$,熵取值就最大,随机变量不确定性最大。
设有随机变量$(X,Y)$,其联合概率分布为$$P(X=x_i,Y=y_j)=p_{ij},i=1,2,…,n;j=1,2,…,m$$条件熵$H(Y|X)$表示在已知随机变量$X$的条件下随机变量Y的不确定性。随机变量X给定的条件下随机变量Y的不确定性。随机变量X给定的条件下随机变量Y的条件熵$H(Y|X)$,定义为X给定条件下Y的条件概率分布的熵对X的数学期望$$H(Y|X)=\sum_{i=1}^{n}{p_iH(Y|X=x_i)}$$这里,$p_i=P(X=x_i),i=1,2,…,n.$
当熵和条件熵中的概率由数据估计得到时,所对应的熵和条件熵分别称为经验熵、经验条件熵。此时,如果有0概率,令$0log0=0$。信息增益表示得知特征X的信息而使得类Y的信息的不确定性缺少的程度。
定义5.2(信息增益)特征$A$对训练数据集D的信息增益$g(D,A)$,定义为集合$D$的经验熵$H(D)$与特征$A$给定条件下$D$的经验条件熵$H(D|A)$之差,即$$g(D,A)=H(D)-H(D|A)$$一般地,熵$H(Y)$与条件熵$H(Y|X)$之差称为互信息。决策树学习中的信息增益等价于训练数据集中类与特征的互信息。
决策树学习应用信息增益准则选择特征。给定训练数据集D和特征A,经验熵$H(D)$表示对数据集$D$进行分类的不确定性。而经验条件熵$H(D|A)$表示在特征$A$给定的条件下对数据集D的不确定性。那么它们的差,即信息增益,就表示由于特征A而使得对数据集D的分类的不确定性减少的程度。显然,对于数据集D而言,信息增益依赖于特征,不同的特征往往具有不同的信息增益。信息增益大的特征具有更强的分类能力。
设训练数据为$D$,$|D|$表示其样本容量,即样本个数。设有$K$个类$C_k$,$k=1,2,…,K$,$|C_k|$为属于类$C_k$的样本个数,$\sum_{k=1}^{K}{|C_k|=|D|}$。设特征$A$有$n$个不同的取值${a_1,a_2,…,a_n}$,根据特征A的取值将D划分为n个子集$D_1,D_2,…,D_n$,$|D_i|$为$D_i$的样本数量,$\sum_{i=1}^{n}{|D_i|=|D|}$。记子集$D_i$中属于类$C_k$的样本的集合为$D_{ik}$,即$D_{ik}=D_i\cap C_k$,$D_{ik}$为$D_{ik}$的样本个数。于是信息增益的算法如下:
算法5.1(信息增益的算法)
输入:训练数据$D$和特征$A$;
输出:特征$A$对训练数据集$D$的信息增益$g(D,A)$
(1)计算数据集D的经验熵$H(D)$$$H(D)=-\sum_{k=1}^{K}{\frac{|C_k|}{|D|} log_2{\frac{C_k}{D}}}$$
(2)计算特征A对数据集D的经验条件熵$H(D|A)$$$H(D|A)=\sum_{i=1}^{n}{\frac{|D_i|}{|D|}H(D)}=-\sum_{i=1}^{n}{\frac{|D_{ik}|}{|D_i|}log_2\frac{|C_k|}{|D|}}$$
(3)计算信息熵$$g(D,A)=H(D)-H(D|A)$$
信息增益算法的实现
代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68import numpy as np
def get_data():
dataSet = [[0, 0, 0, 0, 0],
[],
[],
[],
[],
[],
[],
[],
[],
[],
[],
[],
[],
[],
[]]
X=np.zeros([len(dataSet),4])
Y=np.zeros(len(dataSet))
for i in range(len(dataSet)):
for t in range(4):
X[i][t]=dataSet[i][t]
Y[i]=dataSet[i][4]
return X,Y
def empirical_entropy(x):
x_value_list = set([x[i] for i in range(x.shape[0])])
ent = 0.0
for x_value in x_value_list:
p = float(x[x == x_value].shape[0]) / x.shape[0]
logp = np.log2(p)
ent -= p * logp
return ent
def empirical_conditional_entropy(x, y):
x_value_list = set([x[i] for i in range(x.shape[0])])
# print(x_value_list)
ent = 0.0
for x_value in x_value_list:
sub_y = y[x == x_value]
temp_ent = empirical_entropy(sub_y)
ent += (float(sub_y.shape[0]) / y.shape[0]) * temp_ent
return ent
def information_gain(x,y):
base_ent = empirical_entropy(y)
condition_ent = empirical_conditional_entropy(x, y)
ent_grap = base_ent - condition_ent
return ent_grap
if __name__ == '__main__':
X,Y=get_data()
print("*"*10,"X","*"*10)
print(X)
print("*"*10,"Y","*"*10)
print(Y)
print("*"*10,"信息增益","*"*10)
for i in range(X[0].shape[0]):
print("g(D,A_"+str(i)+"): %.3f " % (information_gain(X[:,i],Y)))
结果: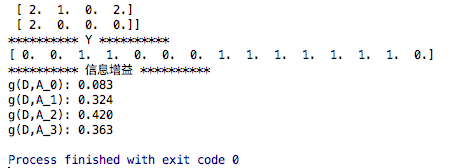
信息增益比
信息增益值的大小是相对于训练数据集而言的,并没有绝对意义。在分类问题困难时,也就是说在训练数据集的经验熵大的时候,信息增益值会偏大。反之,信息增益值会偏小。使用信息增益比可以怼这一问题进行校正。这是特征选择的另一准则。
定义5.3(信息增益比)特征A对训练数据集D的信息增益比$g_R(D,A)$定义为其信息增益$g(D,A)$与训练数据集D的经验熵$H(D)$之比:$$g_R(D,A)=\frac{g(D,A)}{H(D)}$$其中,$H_A(D)=-\sum_{i=1}^{n}log_2\frac{D_i}{D}$,n是特征A取值的个数。
决策树的生成
ID3算法
ID3算法的核心是在决策树各个节点上应用信息增益准则选择特征,递归地构建决策树。具体方法是:从根结点开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子结点;再对子结点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择为止。最后得到一棵决策树。ID3相当于用极大似然法进行概率模型的选择。
算法5.2(ID3算法)
输入:训练数据集D,特征集$A$,阈值$\varepsilon$
输出:决策树$T$
(1)若D中所有实例属于同一类$C_k$,则$T$为单结点树,并将类$C_k$作为该结点的类标记,返回$T$。
(2)若$A\ne\emptyset$,则$T$为单结点树,并将$D$中实例数最大的类$C_k$作为该结点的类标记,返回$T$;
(3)否则,按算法5.1计算$A$中各特征对$D$的信息增益,选择信息增益最大的特征$A_g$;
(4)如果$A_g$的信息增益小于阈值$\varepsilon$,则置$T$为单结点树,并将$D$中实例数最大的类$C_k$作为该结点的类标记,返回$T$;
(5)否则,对$A_g$的每一可能值$a_i$,依$A_g=a_i$将$D$分割为若干非空子集$D_i$,将$D_i$中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树$T$,返回$T$;
(6)对$i$个子结点,以$D_i$为训练集,以$A-{A_g}$为特征集,递归地调用步(1)~(5),得到子树$T_i$,返回$T_i$。
C4.5的生成算法
C4.5算法与ID3算法相似,是对其的一种改进,C4.5在生成的过程中,用信息增益比来选择特征。
算法5.3(C4.5的生成算法)
输入:训练数据集$D$,特征集$A$,阈值$\varepsilon$;
输出:决策树$T$;
(1)如果$D$中所有实例属于同一类$C_k$,则置$T$为单结点树,并将$C_k$作为该结点的类,返回$T$;
(2)若$A\ne\emptyset$,则$T$为单结点树,并将$D$中实例数最大的类$C_k$作为该结点的类标记,返回$T$;
(3)否则,按算法5.10计算$A$中各特征对$D$的信息增益比,选择信息增益比最大的特征$A_g$;
(4)如果$A_g$的信息增益小于阈值$\varepsilon$,则置$T$为单结点树,并将$D$中实例数最大的类$C_k$作为该结点的类标记,返回$T$;
(5)否则,对$A_g$的每一可能值$a_i$,依$A_g=a_i$将$D$分割为若干非空子集$D_i$,将$D_i$中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树$T$,返回$T$;
(6)对$i$个子结点,以$D_i$为训练集,以$A-{A_g}$为特征集,递归地调用步(1)~(5),得到子树$T_i$,返回$T_i$。
决策树的剪枝
决策树通过递归来产生决策树,这样产生的树往往对训练数据分了很精确,但是在未知数据中不准确,即出现过拟合的现象。在决策树学习中将已生成的树进行简化的过程称为剪枝,具体地,剪枝从已生成的树上裁掉一些子树或叶结点,并将其根结点或父结点作为叶结点,从而简化决策树模型。
剪枝所用的损失函数
决策树的剪枝往往通过极小化决策树整体的损失函数或代价函数来实现。设树$T$的叶结点个数为$|T|$,t是树$T$的叶结点,该叶结点有$N_t$个样本点,其中k类的样本点有$N_{tk}$个,$k=1,2,…,K$,$H_t(T)$为叶结点$t$上的经验熵,$\alpha\ge0$为参数,则决策树学习的损失函数可以定义为$$C_{\alpha}(T)=\sum_{t=1}^{|T|}{N_tH_t(T)+\alpha{|T|}}\tag{5.11}$$其中经验熵为$$H_t(T)=-\sum_{k}\frac{N_{tk}}{N_t}log\frac{N_{tk}}{N_t}\tag{5.12}$$在损失函数中,将式(5.11)右端的第1项记作$$C(T)=\sum_{t=1}^{|T|}=N_tH_t(T)=-\sum_{t=1}^{|T|}\sum_{k=1}^{K}N_{tk}log\frac{N_{tk}}{N_t}\tag{5.13}$$这时有$$C_{\alpha}(T)=C(T)+\alpha{|T|}\tag{5.14}$$式(5.14)中,$C(T)$表示模型对训练数据的预测误差,即模型与训练数据的拟合度。$|T|$表示模型复杂度,参数$\alpha\ge0$控制两者之间的影响。较大的$\alpha$促使选择简单的模型,较大的$\alpha$促使选择较复杂的模型(树)。$\alpha=0$意味着只考虑模型与训练数据的拟合程度,不考虑模型的复杂度。
式(5.11)或式(5.14)定义的损失函数的极小化等价于正则化的极大似然估计。所以,利用损失函数最小原则进行剪枝就是用正则化的极大似然估计进行模型选择。
图5.6就是决策树剪枝过程的示意图。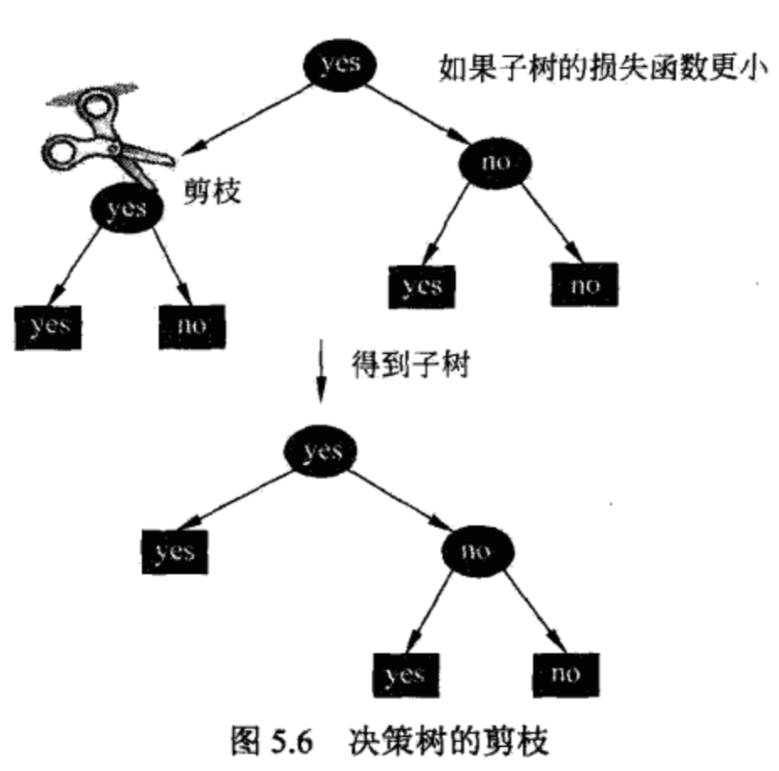
算法5.4(树的剪枝算法)
输入:生成算法产生的整个树$T$,参数$\alpha$;
输出:修剪后的子树$T_\alpha$。
(1)计算每个结点的经验熵。
(2)递归地从树的叶结点向上回缩。
设一组叶结点回缩到其父结点之前与之后的整体树分别为$T_B$与$T_A$,其对应的损失函数值分别是$C_\alpha(T_B)$与$C_\alpha(T_A)$,如果$$C_\alpha(T_A)\le C_\alpha(T_B)\tag{5.15}$$则进行剪枝,即将父结点变成新的叶结点。
(3)返回(2),直至不能继续为止,得到损失函数最小的子树$T_\alpha$。
注意,式(5.15)只需考虑两个树的损失函数的差,其计算可以在局部进行。
- 本文链接:https://netycc.com/2018/10/19/决策树的原理及实现/
- 版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 CN 许可协议。转载请注明出处!
分享